- Page d'accueil
- Ressources
- Blog
- Pourquoi opter pour un réseau informatique à haute disponibilité ?


Même lorsqu’on met en place une infrastructure réseau fiable et robuste, de multiples aléas peuvent survenir. Piratage, brusque montée en charge, accident matériel, catastrophe naturelle, erreur humaine… Tous ces facteurs sont susceptibles d’entraîner des pannes et de peser sur la productivité des entreprises. Plusieurs d’entre elles font donc le choix de la sérénité, offerte par un réseau informatique à haute disponibilité. Mais comment parvenir à un tel niveau de fiabilité ?
Commençons tout d’abord par expliciter la notion de disponibilité. Cette mesure s’exprime généralement en pourcentage : elle correspond au temps durant lequel un service est effectivement accessible divisé par la durée totale considérée. En général, on parle de haute disponibilité informatique lorsque cette valeur dépasse 98 ou 99 % (ou plus, selon le degré d’exigence).
Une indisponibilité au niveau du réseau risque d’avoir de lourdes conséquences sur une entreprise. Elle peut empêcher ses équipes de travailler, geler les achats de ses clients ou interrompre sa chaîne de production. Ainsi, certaines applications sont confrontées à des exigences élevées en matière de disponibilité, afin de satisfaire aux besoins critiques de fiabilité.
C’est pourquoi ce critère occupe une place importante dans le Service Level Agreement (SLA), conclu entre un fournisseur et un client. Ce document recense les différents objectifs à atteindre par le prestataire informatique en matière de qualité de service. Outre cette caractéristique, le SLA peut également inclure le temps de réponse, la satisfaction des utilisateurs, etc.
Afin de limiter au maximum les risques d’indisponibilité du réseau informatique d'une entreprise (WAN, LAN et/ou WiFi), plusieurs leviers peuvent être actionnés. Voici quelques-uns des principes majeurs sur lesquels ils s’appuient.
En premier lieu, la technique dite du « load balancing » (« répartition de charge ») peut favoriser une architecture à haute disponibilité. Elle consiste à distribuer intelligemment les flux sur plusieurs équipements, de sorte à éviter leur surcharge.
Le « clustering » (« regroupement en grappes ») s’inscrit dans le même ordre d’idées. Il s’agit de mettre en commun plusieurs équipements, tels que des serveurs, qui fonctionnent comme un seul et même système. Une telle infrastructure, notamment dans le cadre d’un réseau, permet ainsi de répartir la charge et d’assurer une meilleure fiabilité.
Enfin, le « failover » (« basculement ») intervient en cas d’anomalie majeure. En effet, il vise à rediriger une requête d’un serveur à un autre, lorsque le premier est confronté à une panne. Ce qui laisse le temps d’identifier l’origine du dysfonctionnement et de résoudre le problème.
Vous l’aurez compris à travers les différentes solutions exposées ci-dessus : la redondance joue un rôle clé dans la haute disponibilité. Elle offre en effet une réactivité précieuse, un équipement pouvant se substituer à un autre en cas de dysfonctionnement. Cependant, il ne suffit pas de dupliquer une machine pour obtenir un système parfaitement résilient. Il convient également d’établir des règles de fonctionnement, en s’appuyant notamment sur les principes précédents (load balancing, clustering, failover…). Mais aussi de reproduire la redondance réseau à différents niveaux.
Premièrement, une entreprise a tout intérêt à prévoir une redondance de son accès à Internet professionel. Car si ce dernier ne repose, par exemple, que sur un unique lien de collecte, l’organisation pourrait se retrouver paralysée en cas d’incident relatif à cette arrivée d'internet. Par conséquent, il peut être utile de prévoir un accès complémentaire, soit par la même technologie, soit par une technologie différente.
Ex : Plutôt que d'opter pour un lien unique à 200 Mbps en fibre optique, je vais m'orienter vers deux liens fibre optique de 100 Mbps fournis par des opérateurs de collecte différents. Je disposerai donc de 200 Mbps en temps normal et en cas d'incident sur une de mes arrivées fibre, mon entreprise bénéficiera toujours de 100 Mbps disponibles.
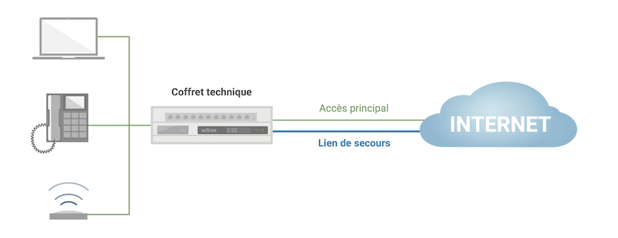
Le principe de redondance de l'accès à internet illustré
Ensuite, une redondance des switchs s’avère également judicieuse pour la haute disponibilité du réseau local (aussi appelé "réseau LAN"). Ces équipements jouent le rôle de commutateurs, en orientant les flux de données vers les bons destinataires. Leur importance est donc cruciale au sein de l’infrastructure. D’où l’intérêt de les « redonder ».
Ex : Je choisis de construire mon coeur de réseau local autour de switchs en stack. Si un dysfonctionnement survient sur l'un d'entre eux, le coeur de réseau sera toujours fonctionnel et mon réseau local également.
Enfin, la même méthode peut s’appliquer à un réseau WiFi. Il est ainsi possible de couvrir une même zone à l’aide de deux bornes. Lorsque l’une d’elles cesse de fonctionner, l’autre continue alors d’offrir une connectivité suffisante, afin d’éviter toute interruption de service.
Ex : Au lieu de définir le juste nombre de bornes pour couvrir un espace, je vais augmenter ce nombre de 30 à 40% et les positionner de sorte qu'elles ne créent pas d'interférences entre elles. Ce maillage rapproché permettra à une borne WiFi de prendre le relais d'une autre en cas de dysfonctionnement.

Représentation visuelle de la redondance WiFi
(n'illustre pas les questions d'interférences à prendre en considération lors de l'implantation des bornes)

