Anche quando viene realizzata un'infrastruttura di rete affidabile e robusta, molte cose possono andare storte. Un hackeraggio, un aumento improvviso del carico, un incidente hardware, una catastrofe naturale, un errore umano... Tutti questi fattori possono portare a guasti e pesare sulla produttività delle aziende. Molte aziende scelgono quindi la tranquillità offerta da una rete informatica ad alta disponibilità. Ma come si raggiunge questo livello di affidabilità?
La disponibilità come fattore chiave dello SLA (Service Level Agreement)
Innanzitutto, spieghiamo il concetto di disponibilità. Questa misura è generalmente espressa in percentuale: corrisponde al tempo durante il quale un servizio è effettivamente accessibile diviso per il tempo totale considerato. In generale, si parla di alta disponibilità informatica quando questo valore supera il 98 o il 99% (o più, a seconda del grado di esigenza).
Un'indisponibilità a livello di rete può avere gravi conseguenze per un'azienda. Può impedire al personale di lavorare, bloccare gli acquisti dei clienti o interrompere la produzione. Pertanto, alcune applicazioni devono soddisfare requisiti di elevata disponibilità per soddisfare esigenze critiche di affidabilità.
Ecco perché questo criterio svolge un ruolo importante nel Service Level Agreement (SLA) tra un fornitore e un cliente. Questo documento elenca i vari obiettivi di qualità del servizio che il fornitore di servizi IT deve raggiungere. Oltre a questa caratteristica, lo SLA può includere anche i tempi di risposta, la soddisfazione degli utenti, ecc.
Come garantire l'alta disponibilità di una rete informatica?
Per limitare il più possibile i rischi di indisponibilità della rete informatica aziendale (WAN, LAN e/o WiFi), si possono attivare diverse leve. Ecco alcuni dei principali principi su cui si basano.
In primo luogo, la tecnica nota come “load balancing" (bilanciamento del carico) può favorire un'architettura ad alta disponibilità. Consiste nel distribuire in modo intelligente i flussi su più dispositivi, per evitare di sovraccaricarli.
Il “clustering” (raggruppamento in pacchetti) è un approccio simile. Si tratta di mettere in comune diversi dispositivi, come i server, che funzionano come un unico sistema. Un'infrastruttura di questo tipo, in particolare nel contesto di una rete, consente di distribuire il carico e di garantire una migliore affidabilità.
Infine, il “failover” viene utilizzato in caso di guasto grave. Ha lo scopo di reindirizzare una richiesta da un server a un altro quando il primo si trova di fronte a un guasto. In questo modo si ha il tempo di identificare la causa del malfunzionamento e di risolvere il problema.
Su quale parte dell'infrastruttura di rete si applica l'alta disponibilità?
Come avrete capito dalle varie soluzioni descritte in precedenza, la ridondanza gioca un ruolo fondamentale nell'alta disponibilità. Offre una preziosa reattività, in quanto un'apparecchiatura può sostituirne un'altra in caso di malfunzionamento. Tuttavia, non è sufficiente duplicare una macchina per ottenere un sistema perfettamente resiliente. È inoltre necessario stabilire delle regole operative, basate in particolare sui principi precedenti (load balancing, clustering, failover...). Ma anche per riprodurre la ridondanza della rete a diversi livelli.
In primo luogo, è nell'interesse di un'azienda fornire una ridondanza per l'accesso professionale a Internet. Se si basa, ad esempio, su un unico link di raccolta, l'organizzazione potrebbe trovarsi paralizzata in caso di incidente relativo a questo accesso a Internet. Pertanto, può essere utile fornire un accesso supplementare, attraverso la stessa tecnologia o un'altra.
Esempio: invece di optare per un singolo collegamento in fibra da 200 Mbps, opterò per due collegamenti in fibra da 100 Mbps forniti da diversi operatori. Avrò quindi a disposizione 200 Mbps in tempi normali e, in caso di incidente su una delle mie connessioni in fibra, la mia azienda avrà comunque a disposizione 100 Mbps.
-IT.jpg?width=618&name=illustration-lien-secours-(redondance)-IT.jpg)
Il principio dell'accesso ridondante a Internet
In secondo luogo, la ridondanza degli switch è importante anche per l'alta disponibilità della rete locale (nota anche come LAN). Questi dispositivi fungono da interruttori, indirizzando i flussi di dati ai giusti destinatari. La loro importanza è quindi fondamentale all'interno dell'infrastruttura. Da qui l'interesse per la "ridondanza".
Esempio: ho scelto di costruire il nucleo della mia rete locale attorno a switch impilati. Se si verifica un malfunzionamento su uno di essi, la rete principale sarà ancora funzionante e lo sarà anche la mia rete locale.
Infine, lo stesso metodo può essere applicato a una rete WiFi. È possibile coprire la stessa area con due terminali. Quando uno di essi smette di funzionare, l'altro continua a fornire una connettività sufficiente, in modo da non interrompere il servizio.
Esempio: invece di definire il numero giusto di access point per coprire uno spazio, aumenterò questo numero del 30-40% e li posizionerò in modo che non interferiscano l'uno con l'altro. Questo stretto collegamento consente a un terminale WiFi di subentrare a un altro in caso di malfunzionamento.
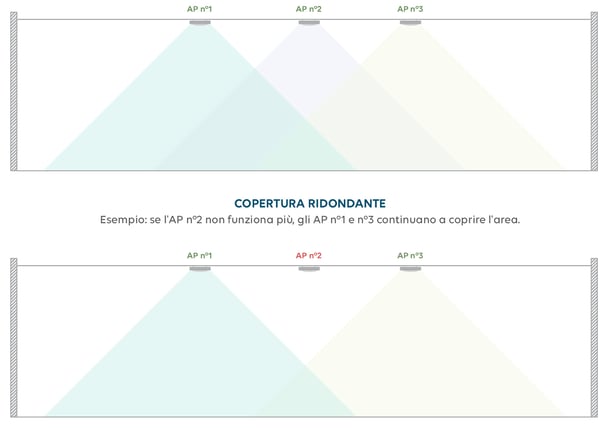
Rappresentazione visiva della ridondanza WiFi
(non illustra i problemi di interferenza da prendere in considerazione quando si posizionano gli access point)




